Membership inference attacks (MIAs) attempt to predict whether a particular datapoint is a member of a target model's training data. Despite extensive research on traditional machine learning models, there has been limited work studying MIA on the pre-training data of large language models (LLMs). We perform a large-scale evaluation of MIAs over a suite of language models (LMs) trained on the Pile, ranging from 160M to 12B parameters. We find that MIAs barely outperform random guessing for most settings across varying LLM sizes and domains. Our further analyses reveal that this poor performance can be attributed to (1) the combination of a large dataset and few training iterations, and (2) an inherently fuzzy boundary between members and non-members. We identify specific settings where LLMs have been shown to be vulnerable to membership inference and show that the apparent success in such settings can be attributed to a distribution shift, such as when members and non-members are drawn from the seemingly identical domain but with different temporal ranges. We release our code and data as a unified benchmark package that includes all existing MIAs, supporting future work.
We identify several key factors that may contribute to the decreased performance of MIAs on LLMs.
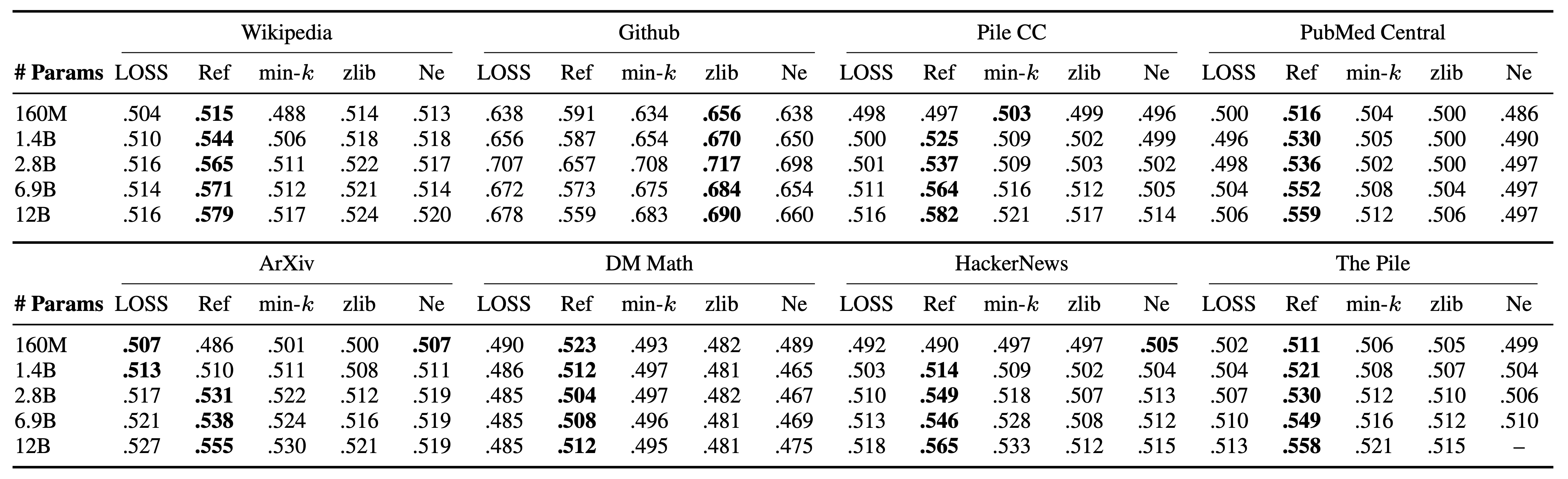
Training Data Size
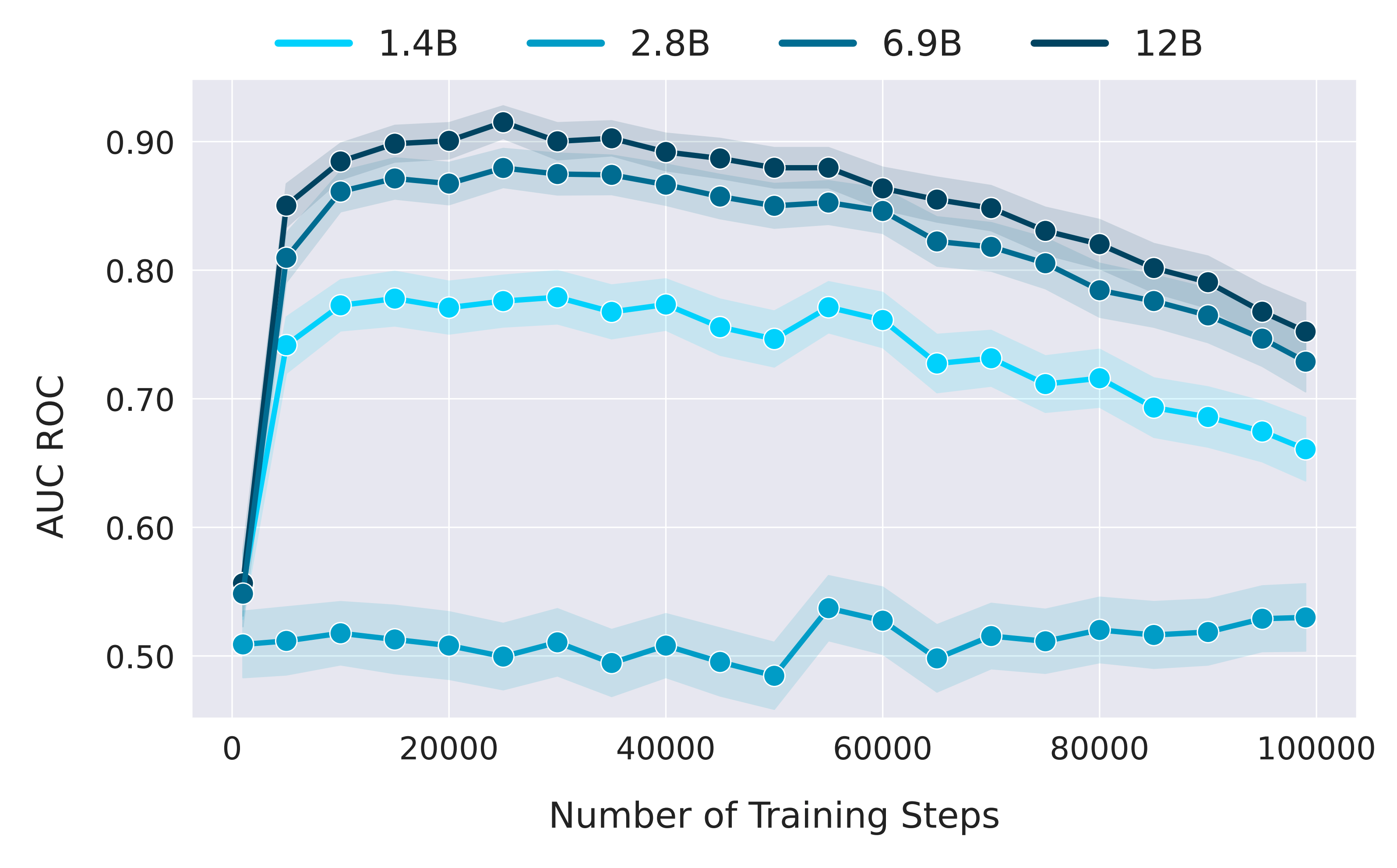 We notice a common pattern in MIA performance: it begins somewhat randomly, then quickly improves over the initial few
thousand steps before declining across subsequent checkpoints. We speculate the initial low performance is due to the
model warming up in training, with high losses across both member and non-member samples. We believe the rapid rise and then gradual decline
in performance are because the data-to-parameter-count ratio is smaller early in training and the model may tend to
overfit, but generalizes better as training progresses.
We notice a common pattern in MIA performance: it begins somewhat randomly, then quickly improves over the initial few
thousand steps before declining across subsequent checkpoints. We speculate the initial low performance is due to the
model warming up in training, with high losses across both member and non-member samples. We believe the rapid rise and then gradual decline
in performance are because the data-to-parameter-count ratio is smaller early in training and the model may tend to
overfit, but generalizes better as training progresses.
Number of Training Epochs
Increasing the number of effective epochs corresponds to an increase in attack performance.
While Muennighoff et al. shows training for multiple epochs helps improve performance, our results suggest
that such multi-epoch training (and/or large upsampling factors that effectively increase epoch count) may increase
training data leakage. Essentially, near-one epoch training of LLMs leads to decreased MIA performance.
See more results in our paper
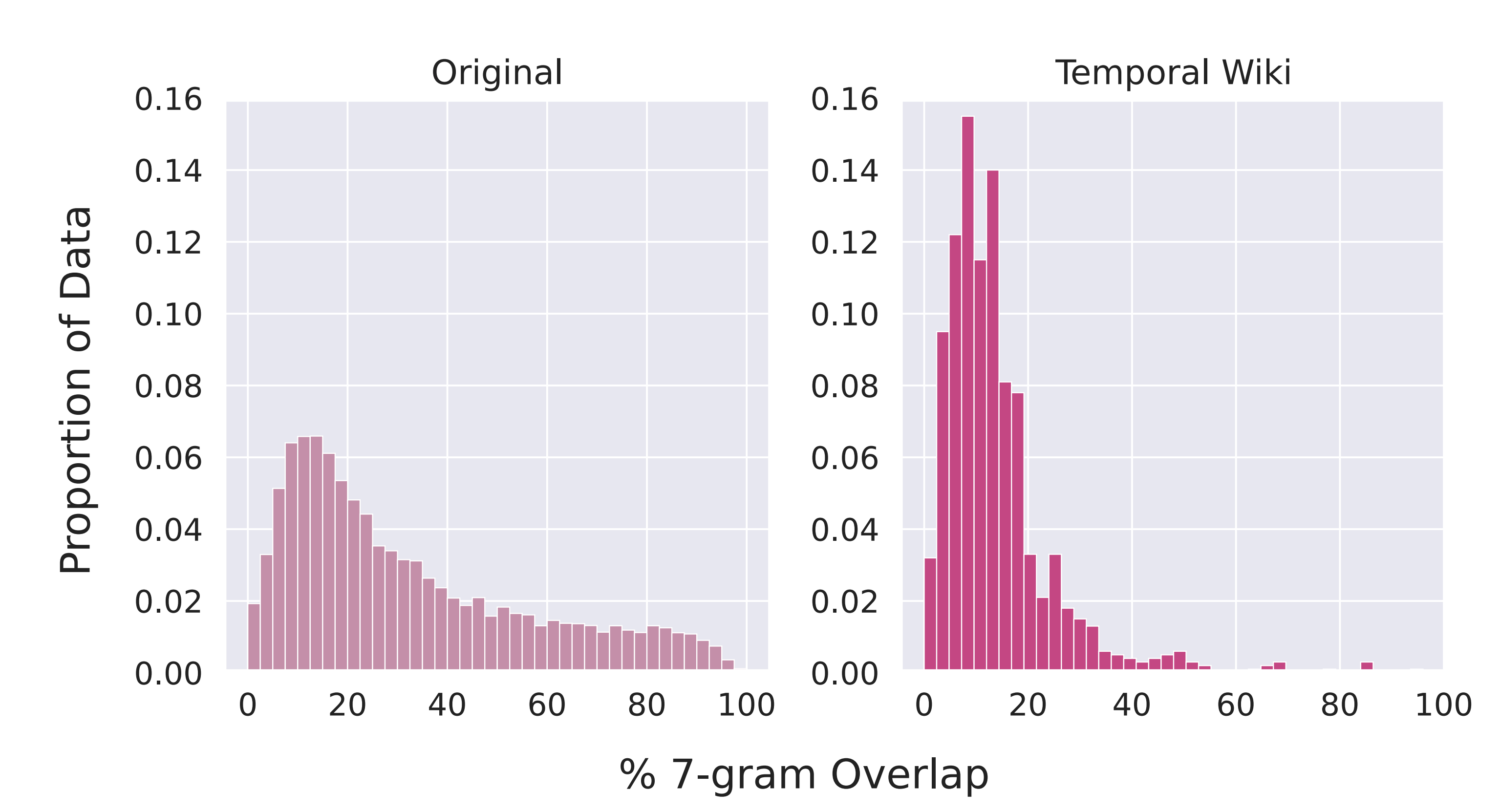
The way membership is defined in the standard membership game treats information leakage as a binary outcome. While metrics are aggregated over multiple records/instances to provide a sense of "how" much is leaked, the binary membership outcome itself may be at odds with what adversaries and privacy auditors care about: information leakage. This is especially true for generative models, where guessing the membership of some record via other sufficiently close records can be useful. We start with a simple experiment: generating modified member records by replacing n random tokens in a given record with tokens randomly sampled from the model's vocabulary. We repeat this for 20 trials and visualize the distribution for MIA scores below.
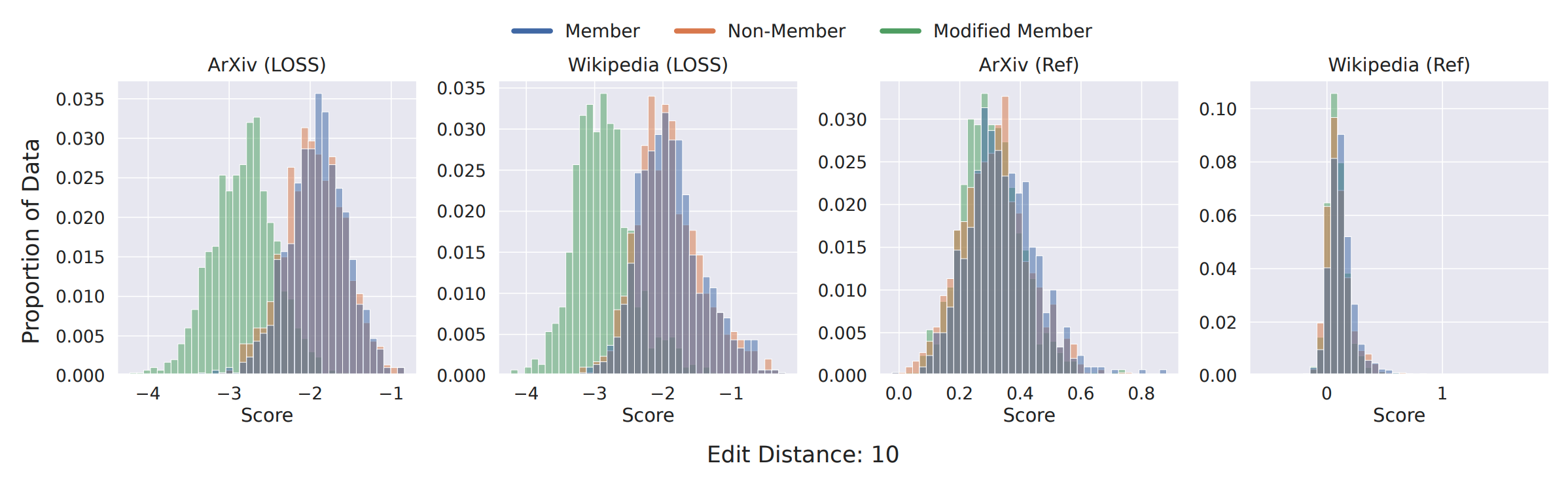
We observe similar trends with neighbors close semantically. We hope that these experiments can demonstrate that an ideal distance function (for defining "neighborhood" of a record)
should combine the benefits of lexical distance and semantics.
Such observations also motivate a fully semantic MI game, where a neighbor member may be defined by its proximity to an exact
member in a semantic embedding space.
Impact of other innate characteristics: Other factors inherent to attacking LLMs, such as the diversity of training data may also contribute to the difficulty of membership inference against LLMs. State-of-the-art LLMs are trained on highly diverse data, rather than being domain-specific. It is thus likely that increased pre-training data diversity can lower vulnerability to MIAs. Rethinking what "membership" means: The high overlap between member and non-member samples from the same domain creates ambiguity in determining membership. Non-members sharing high overlap with members may not be members by exact match standards but may contain meaningful identifiers that leak information. There is thus a need, especially for generative models, to consider membership not just for exact records but for a neighborhood around records. Privacy auditing: Our results suggest two possibilities: (1) data does not leave much of an imprint, owing to characteristics of the pre-training process at scale, and (2) the similarity between in and out members, coupled with huge datasets, makes this distinction fuzzy, even for an oracle. Having a better understanding of the first possibility is especially critical for privacy audits. While it may be possible to increase leakage via stronger attacks in such a scenario, the second scenario requires rethinking the membership game itself. In the meanwhile, special care should thus be taken to avoid unintentional distributional shifts while constructing non-members for MIA benchmark construction.
@inproceedings{duan2024membership,
title={Do Membership Inference Attacks Work on Large Language Models?},
author={Michael Duan and Anshuman Suri and Niloofar Mireshghallah and Sewon Min and Weijia Shi and Luke Zettlemoyer and Yulia Tsvetkov and Yejin Choi and David Evans and Hannaneh Hajishirzi},
year={2024},
booktitle={Conference on Language Modeling (COLM)},
}